How Models Work
Introduction
我们将从概述机器学习模型的工作原理以及它们的使用方式开始。如果您之前做过统计建模或机器学习,这可能会觉得有点基础。别担心,我们很快就会进展到构建强大的模型。
本课程将让您在经历以下情景时构建模型:
您的表亲通过房地产投机赚了数百万美元。由于您对数据科学的兴趣,他提出要与您成为商业伙伴。他提供资金,您提供预测各种房屋价值的模型。
您问表亲过去是如何预测房地产价值的,他说这只是直觉。但更多的问题揭示了他已经从过去见过的房屋中识别出了价格模式,并使用这些模式来对他正在考虑的新房屋进行预测。
机器学习的工作方式相同。我们将从一个叫做决策树的模型开始。还有一些更花哨的模型可以提供更准确的预测。但决策树易于理解,它们是数据科学中一些最佳模型的基本构建块。
为了简单起见,我们将从最简单可能的决策树开始。
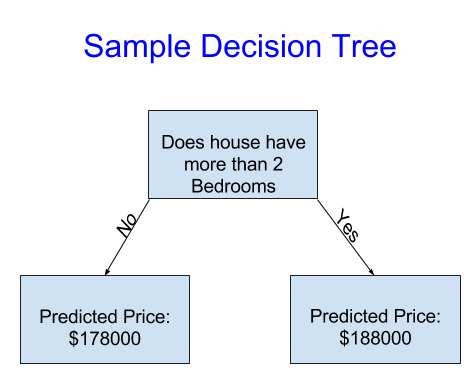
这个决策树将房屋仅分为两类,任何正在考虑的房屋的预测价格是同一类别房屋的历史平均价格。
我们使用数据来决定如何将房屋分成两组,然后再使用数据来确定每组的预测价格。从数据中捕捉模式的这一步被称为拟合或训练模型。用于拟合模型的数据称为训练数据。
模型拟合的细节(例如如何分割数据)足够复杂,我们将留待以后再讨论。模型拟合后,您可以将其应用于新数据,以预测更多房屋的价格。
Improving the Decision Tree
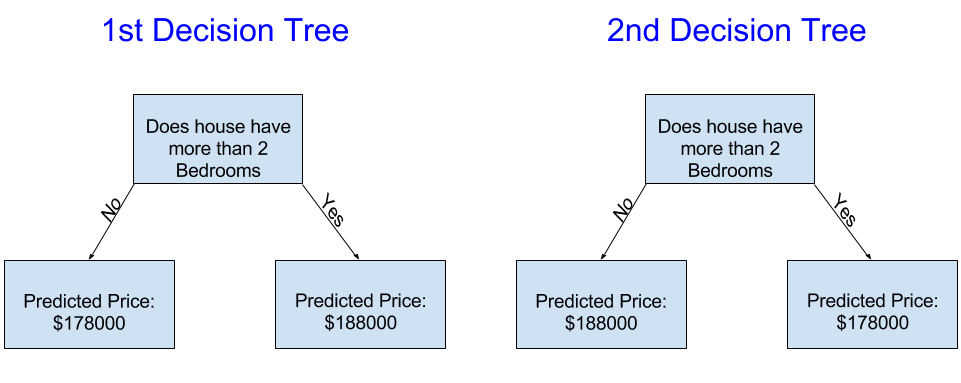
左侧的决策树(决策树1)可能更有意义,因为它捕捉到了拥有更多卧室的房屋往往比拥有较少卧室的房屋售价更高的现实情况。这个模型最大的缺点是它没有捕捉到影响房价的大多数因素,比如卫生间数量、地块大小、位置等。
您可以使用具有更多“分裂”的树来捕捉更多因素。这些被称为“更深层次”的树。一个还考虑了每个房屋地块总面积的决策树可能看起来像这样:
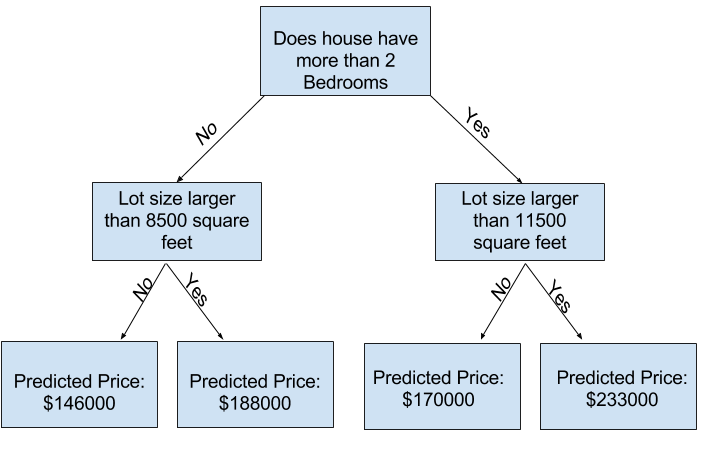
您通过追踪决策树来预测任何房屋的价格,始终选择与该房屋特征相对应的路径。房屋的预测价格位于树的底部。我们进行预测的底部点称为叶节点。
树的分裂和叶节点上的值将由数据决定,所以现在是时候查看您将要使用的数据了。